The Discovery Environment for Relational Information and Versioned Assets (DERIVA) is an open-source, model-driven platform that turns any research dataset — imaging, ‘omics, models, protocols, and much more — into a continuously FAIR, version-controlled, and citable asset.
Built at the USC Information Sciences Institute, the stack has powered a broad array of NIH-funded biomedical research consortia such as FaceBase, PDB-IHM, and the Common Fund Data Ecosystem.
Why DERIVA?
Modern science generates heterogeneous files faster than curators can harmonise them and at an unprecedented breadth and depth. Common tools such as Dropbox or lab wikis can store files, but they don’t track where the data came from or how it has changed; meanwhile, large laboratory information-management systems tend to be rigid and hard to update when researchers switch to new experiments or instruments.
DERIVA sits in the middle:
- Schema-adaptive – scientists edit the ER model; the UI and APIs update automatically.
- Continuous FAIRness – persistent IDs and provenance are minted at ingest, not after publication.
- Self-curation at scale – web, CLI, and desktop tools let labs deposit data while curators review QC dashboards.
- End-to-end versioning – every file revision and database row is traceable and recoverable.
What researchers can do with DERIVA
- Ingest and richly describe diverse scientific assets.
- Query & discover via faceted search, SQL, or Python SDK.
- Link raw data → processed outputs → figures with full provenance.
- Share data collections privately or publicly with DOI landing pages.
- Enforce access control down to the row or object level.
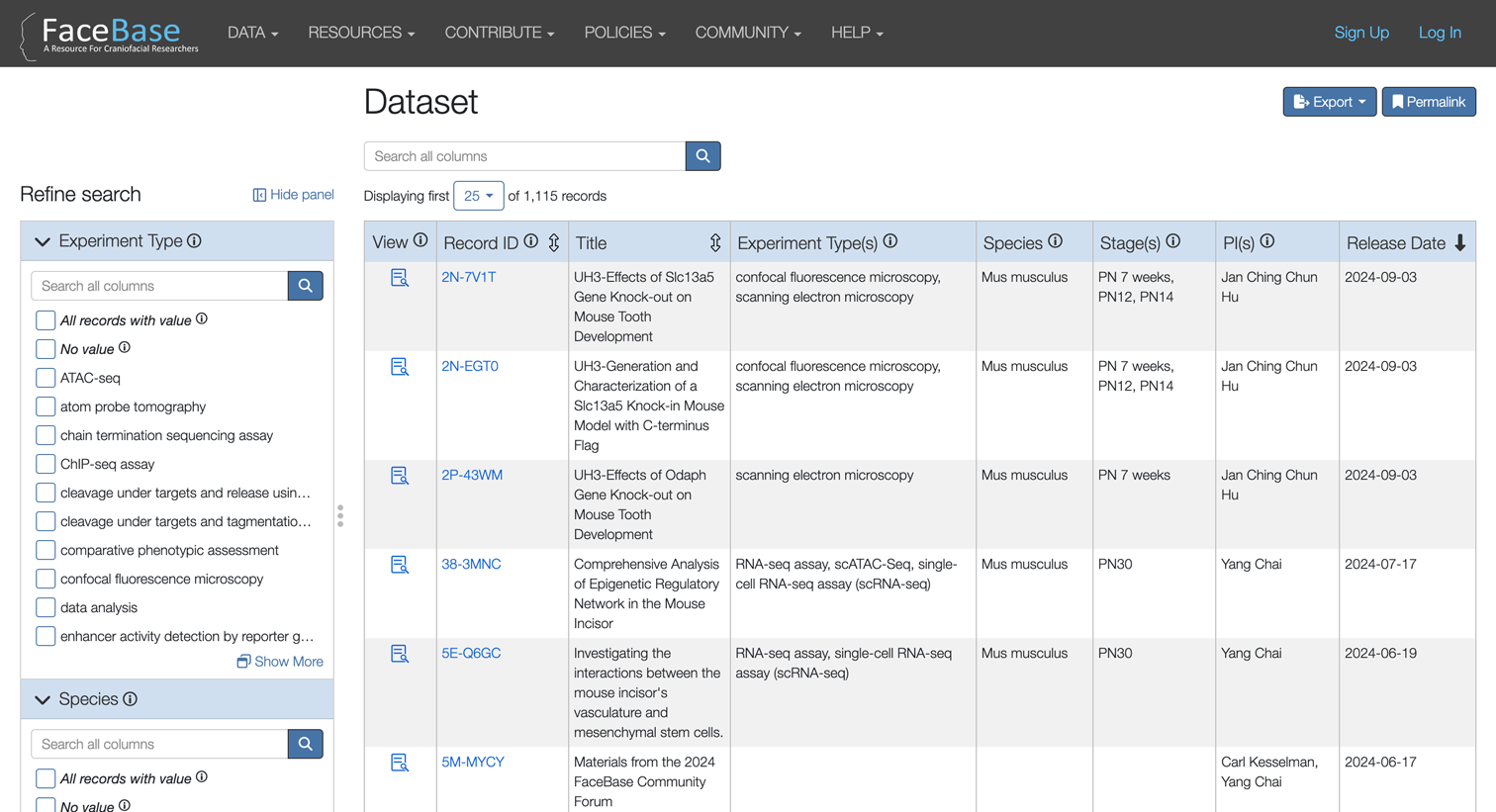 Screenshot of the main search page for FaceBase
Screenshot of the main search page for FaceBase
Core components
| Layer | Component | Purpose |
|---|---|---|
| Client Applications | Chaise (model-driven web UI) deriva-qt (desktop GUI) deriva-cli (bulk ingest) | Curate, browse, and upload data |
| Client Libraries | deriva-py (Python SDK) ERMrestJS (JS client) | Automate ingest, QC, and analytics |
| Server Services | ERMrest (relational metadata) Hatrac (object store) ERMresolve (ID resolver) IOBoxD (export service) | Version data, mint IDs, serve APIs |
| Orchestration | Flow-based automation and scheduled tasks | Validation, DOI minting, QC reports |
All services communicate over open REST/HTTP; deployments range from a single VM to Kubernetes clusters.
Governance & licensing
DERIVA is released under the Apache 2.0 licence. Work is funded by multiple NIH grants (NIDCR, NIDCD, NIDDK, NIGMS, NLM, NEI) and maintained by the Informatics Systems Research Division at USC ISI.